
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- multi-task learning
- 스무고개 Metric
- Convolutional Neural Networks
- 알고리즘
- 장영준
- 딥러닝
- 경제 요약
- aws rds
- 2003 에러
- 프로그래머스
- 미국 이란 전쟁
- cs231
- 2003 error
- 백준 2193
- 리멤버나우
- git password
- pytorch-tutorial
- 프로그래머스 여행경로
- flaks
- 오픈소스
- 웹 독학
- git-lfs
- C++
- 이베이 매각
- 코딩테스트
- flask
- but how?
- 리멤버나우 요약
- 뤼이드
- 110 옮기기
- Today
- Total
Nam's
[신발검색엔진] 06 - 인공지능 모델 배포하기 본문
신발 검색 엔진 Front-end, Back-end 틀을 짜는데 3일,
웹 호스팅을 위한 Lightsail, DB 준비에 1일,
이미지 유사도 모델을 만드는데 3일이 걸렸다.
거의 다 했다고 생각했는데, 이 세가지를 합치는데 5일정도 걸렸다. 인공지능 모델을 서비스로 연결하는데 어려움이 많이 있었다. (사실 아직도 많이 남아있다.)
1. System 구조 설계
2. AI 모델 AWS Lightsail로 옮기기
3. Memory 최적화
1. System 구조 설계
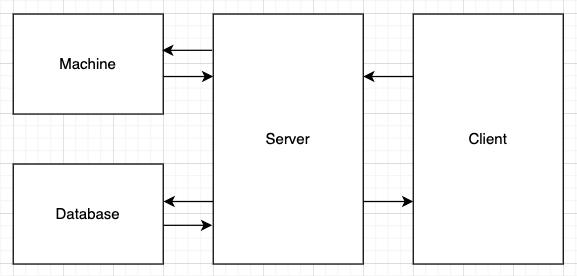
전체 적인 시스템 구조는 위와 같다. Machine이 AI Model을 의미한다.
사용자의 요청에 따라 Server는 Machine을 이용해 비슷한 이미지 후보군을 뽑은 후 Database에서 해당 상품 리스트를 Client에게 전달한다.
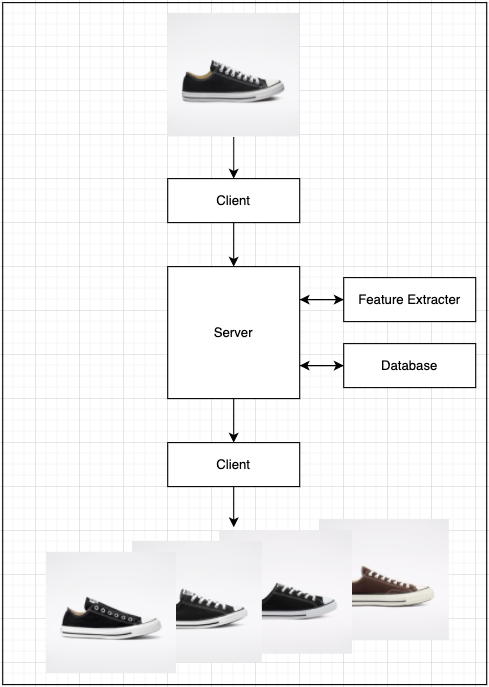
사용자가 검색하기 원하는 이미지를 입력하면, Server는 Machine을 이용해서 Image Featrue Extraction을 진행한다.
추출된 이미지 특징과 미리 뽑아둔 데이터 셋의 Feature Set 과 비교한 후, 가장 유사한 이미지 100장을 고른다.
100장의 이미지에 해당하는 정보를 Database에서 가져와 Client에게 다시 전달한다.
2. AI 모델 AWS Lightsail로 옮기기
인공지능 모델 학습을 위해서 사용할 수 있는 서버가 따로 있는 상황이 아니기 때문에 모델 연구는 Google Colab에서 진행되고 있다. 학습은 Colab에서 하더라도 이미지 유사도 측정은 사용자 인풋 이미지가 있어야 가능하기 때문에 AWS Server에서 모델 예측을 진행해야한다.
먼저, tensorflow, python 등의 버전에 따라서 모델이 Server에서 돌아가지 않을 수도 있기 때문에 버전을 확인한고 requirement.txt 파일을 만들어준다.

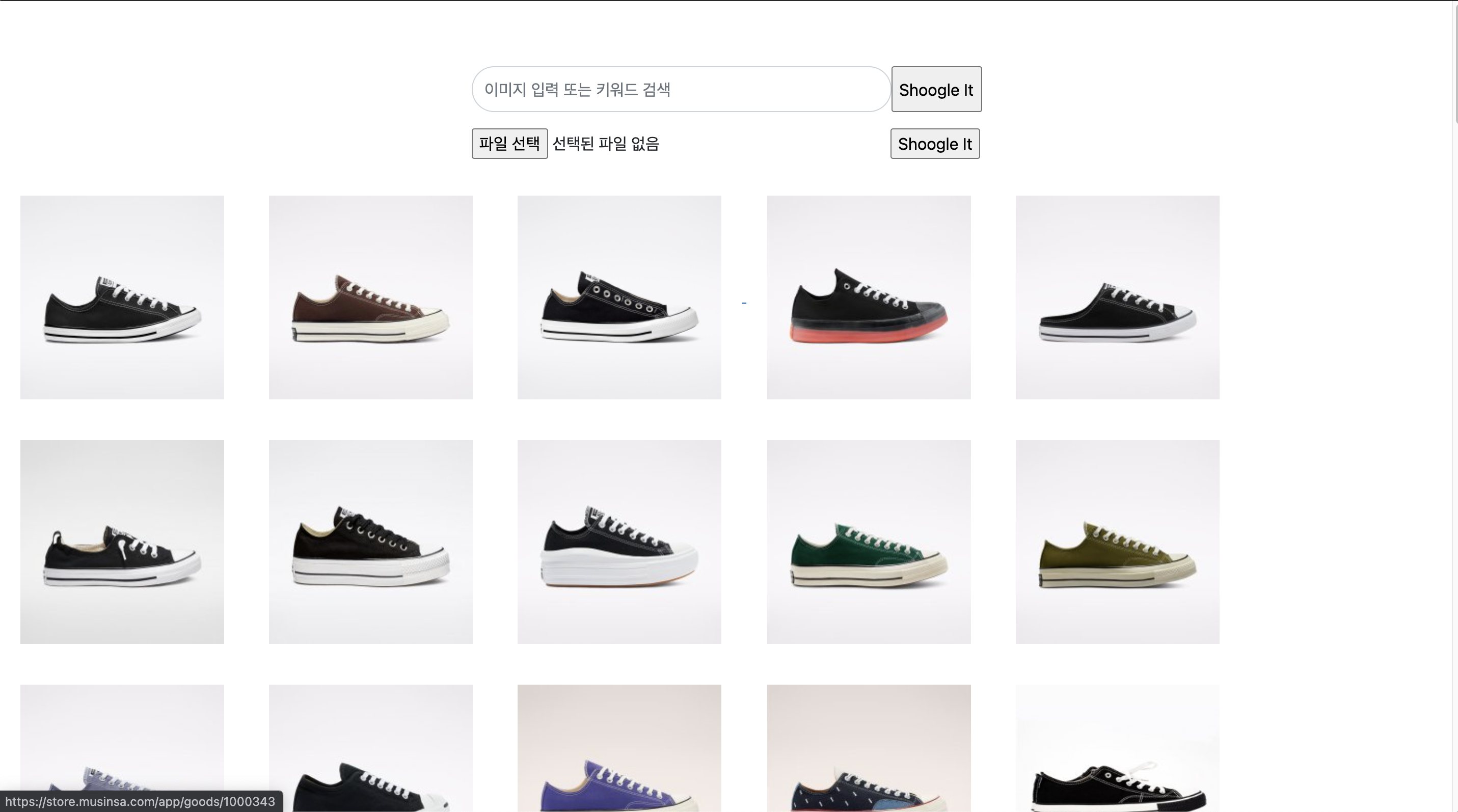
사전에 크롤링해둔 신발 데이터는 26000장으로, Feature Extraction 시간이 꽤 오래 걸린다(약 3시간). 미리 신발 사진들의 Feature Map을 numpy 파일(.npy) 형태로 저장해두면 빠르게 이미지 유사도 검사가 가능하다. 사용자의 이미지만 Feature Extraction을 진행하고 Feature Map과 비교해서 가장 차이가 적은 이미지들을 뽑을 수 있다. [이미지 유사도 측정 모델]
Feature Map .npy 파일은 Colab에서 만들었기 때문에 AWS Server로 옮겨줘야 하는데 파일 크기가 400mb이다. git으로는 기본적으로 100mb가 넘는 파일을 옮길 수 없고, git-lfs를 사용해서 업로드해야했다. [AWS EC2, Lightsail에 git-lfs 설치하기]
추후에 자본이 생긴다면? Server에서 Feature Map을 뽑을 수 있으면 더 좋을 것 같다. 매일 같이 신발 Database가 바뀔 수도 있는 상황에서 매번 Colab을 이용하기는 너무 번거로울 것 같다.
3. Memory 최적화
이제 다 됐다고 생각하고 친구들에게 링크를 보냈는데 예상치 못한 문제가 발생했다. 한번에 두명 이상의 사용자가 이미지 검색을 하면 서버가 다운되는 말도 안되는 문제였다.
Exception happened during training, message: OOM when allocating tensor with shape[26285,4096]문제를 구글링 해보니 26000장의 신발 사진 Feature Map의 크기가 너무 커서 CPU 메모리를 너무 많이 사용해서 발생하는 문제였다. Feature Map의 Feature Vector 개수를 줄여야 하나 고민하다가 Python 구조에 문제가 있다는 것을 알게되었다. (준형아 고맙다ㅜ)
사용자가 Image 검색을 요청할 때마다 400mb의 .npy파일을 load해서 인풋 이미지와 비교하고 있었다. Server는 항상 실행되고 있기 때문에 처음에 Server를 실핼할 때 .npy 파일을 미리 load해두고 사용하면 해결되는 문제였다.
load하는 시간이 줄어드니까 Image 검색 속도 자체도 많이 개선될 수 있었다.
Feature Extractor 모델도 매번 요청 마다 init 해주고 있었는데, Server가 실행될 때 init 해두고 사용하게금 최적화 시킬 수 있었다.
'개발 > Side Project' 카테고리의 다른 글
| [신발검색엔진] 08 - Web UI prototype with Figma (0) | 2021.07.13 |
|---|---|
| [신발검색엔진] 07 - 신발 검색 및 쇼핑에 관한 설문조사 (0) | 2021.07.09 |
| [신발검색엔진] 05 - 이미지 유사도 측정 모델 개발(VGG16) (6) | 2021.06.28 |
| [신발검색엔진] 04 - 이미지 유사도 측정 모델 개발(Autoencoder) (0) | 2021.06.28 |
| [신발검색엔진] 03 개발 1주차 - 웹 구현 Debugging (0) | 2021.06.26 |



