
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- flask
- 알고리즘
- aws rds
- 이베이 매각
- 미국 이란 전쟁
- git-lfs
- C++
- 프로그래머스 여행경로
- 코딩테스트
- 110 옮기기
- but how?
- 리멤버나우 요약
- flaks
- 리멤버나우
- 뤼이드
- 스무고개 Metric
- git password
- 프로그래머스
- 백준 2193
- 2003 error
- 장영준
- 오픈소스
- cs231
- 경제 요약
- 웹 독학
- 딥러닝
- Convolutional Neural Networks
- multi-task learning
- 2003 에러
- pytorch-tutorial
- Today
- Total
Nam's
[머신러닝] Multi-task Learning 설명 본문
이해를 돕기 위한 글이 아닌, 개인적인 학습 목적의 글입니다.
보다 잘 정리되어 있는 자료가 필요하신 분들은
http://yunshengb.com/wp-content/uploads/2017/11/Multi-Task-Machine-Learning.pdf
위 링크와 아래 참고자료들을 참고하시면 좋을 것 같아요.
Multi-task Learning에 대한 이해도가 더 높아지면 잘 정리된 글을 포스팅할 계획입니다.
참고자료
Multitask Learning (1997)
A Survey on Multi-Task Learning (2018)
An overview of Multi-Task Learning in Deep Neural Networks (2017)
https://www.youtube.com/watch?v=UdXfsAr4Gjw&t=1s - Andrew Ng
https://www.youtube.com/watch?v=klFFAndQia8 - Naver D2
Abstract
Multi-Task Learning은 서로 연관 있는 과제들을 동시에 학습함으로써 모든 과제 수행의 성능을 전반적으로 향상시키려는 학습 패러다임이다. 본문에서는 MTL의 특징과 대표 알고리즘 몇 가지를 설명한다. 그다음 MTL이 결합될 수 있는 몇 가지 모델과 MTL을 접목시킬 수 있는 real-world applications를 소개한다.
1. Introduction
머신러닝은 대게 많은 양의 학습 data를 필요로 한다. 특히 딥러닝 neural networks의 수많은 layer와 parameter들을 학습시키기 위해서는 방대한 양의 labeled data가 필요하다. 하지만 의료 data 같이 수집이 어렵거나 비싼 data들이 있다. 이런 경우 딥러닝은 차치하고 얕은 모델들도 학습이 어렵다. 이러한 상황에서, 관련 있는 task들을 동시에 학습시키는 Multi-Task Learning이 좋은 해결 방법이 될 수 있다. 연관 있는 task들을 연결시켜 동시에 학습시킬 때 성능이 향상되는 것을 발견할 수 있었고 MTL 등장의 배경이 되었다.
MTL은 인간이 새로운 것을 학습할 때 이전에 학습 했던 유사경험에 접목시켜 더 빨리 학습하는 것에서 영감을 얻었다. 이러한 점에서 MTL은 Transfer Learning과 많이 유사해 보이지만, 큰 차이점이 있다. MTL의 경우 동시에 학습하는 모든 과제들에서 성능 향상을 도모하지만, Transfer Learning의 경우 target task와 source task가 구분되어 있어서 target task의 학습 향상에 초점을 맞춘다.
2. Notation
MTL model들을 구분하기에 앞서서 몇가지 용어 정리가 필요하다.
Multi-label vs Multi-task
만약 서로 다른 task들이 같은 training data set으로 구성된다면 MTL이 아니라 multi-label learning이나 multi-output regression과 다를 바 없어진다. 따라서 MTL은 각 task가 서로 다른 training set으로 구성된다.
Homogeneous-feature MTL vs Heterogeneous-feature MTL
이 때, 각 training set이 같은 feature space에 놓여 있다면 homogeneous-feature MTL이라고 한다. 그렇지 않은 경우는 heterogeneous-feature MTL이라고 하는데, heterogeneous MTL과 구분할 필요가 있다.
Homogeneous MTL vs Heterogeneous MTL
두 MTL의 구분은 각 task의 학습 방법의 단일성이 결정한다. 각 task들이 동일하게 supervised learning(classification)을 사용한다면, homogeneouse MTL이라고 할 수 있다. 만약 그렇지 않고 각 task들이 classification과 regression 혹은 supervised와 semi-supervised or reinforcement learning 같이 다른 학습 방법을 사용한다면 heterogeneous MTL이라고 부른다.
특별한 언급이 없다면 기복적으로 MTL은 대부분 homogeneous-feature MTL과 homogeneous MTL이다.
3. Motivation
Machine Learning, Deep Learning
↓
많은 Data 필요
↓
Data 부족한 경우 발생 (ex 의료 data)
↓
인간의 학습 방법:
이전의 학습 경험을 현재의 학습에 접목시켜 더 빠르게 학습한다.
↓
연관성 있는 여러가지 Task를 동시에 학습시킨다.
learned representation을 공유
↓
performance improved
4. MTL Models
다음으로 MTL을 구분하기 위한 세 가지 이슈가 있다: when to share, what to share, how to share
1. When to share: Task를 언제까지 공통으로 학습 시킬 것인가? Task간에 언제 지식을 전달할 것인가?
(Hard sharing과 Soft Sharing 예시를 보면 이해하기 쉽다.)
2. What to share: Feature, instance and parameter. This paper mainly review feature and parameter based MTL.
3. How to share:
Feature-based MTL : feature learning approach
Parameter-based MTL : low-rank approach, task clustering apprach, task relation learning approach, and decomposition approach.
다른 방법으로 MTL Model을 분류할 수도 있다.
Hard Sharing

hard sharing의 경우 같은 뿌리 모델에서 시작되어 나중에 각각의 represenation을 학습하는 방식이다. 전통적으로 이 방식이 많이 사용되어 왔다.
Soft Sharing
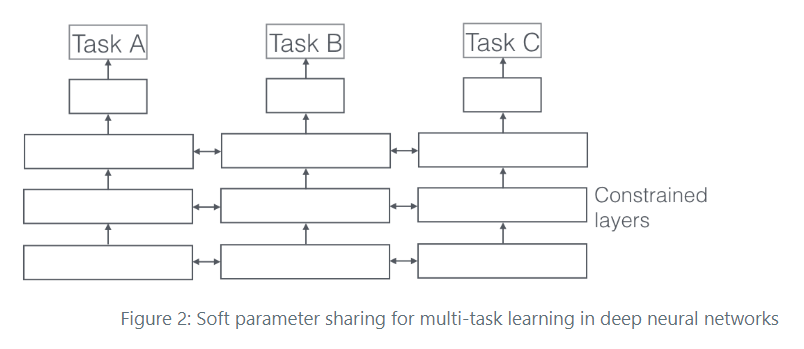
반면, soft sharing은 각각 다른 모델에서 시작해서 중간중간 정보를 공유한다. 최근에 와서 연구가 활발해지고 있다.
5. Pros and Cons
< 장점 >
Knowledge Transfer (Eavesdropping)
- task A를 학습하면서 얻은 유용한 정보가 다른 task B, task C에 좋은 영향을 준다.
Overfitting 감소
- 여러 task를 동시에 맞추기 위해 보다 generalized 된 shared representation을 학습한다.
Computational Efficiency
여러 task를 동시에 학습한다.
Real-world Application에 잘맞다
현실에서는 매우 다양한 task가 한 번에 요구된다. ex) 무인차
단점:
Negative Transfer
- 다른 task에 악영향을 끼치는 task가 있을 수 있다.
Task Balancing의 어려움
- task 마다 학습 난이도가 크게 차이 나면 수렴하지 않거나, 강력하지 않다.
6. Applications
MTL has many applications in various areas including computer vision, bioinformatics, health informatics, speech, natural language processing, web applications, ubiquitous computing, and so on.