
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- aws rds
- 110 옮기기
- 뤼이드
- git password
- 2003 error
- cs231
- 알고리즘
- C++
- 경제 요약
- but how?
- 프로그래머스 여행경로
- 스무고개 Metric
- multi-task learning
- 딥러닝
- 백준 2193
- Convolutional Neural Networks
- flaks
- 2003 에러
- 이베이 매각
- 미국 이란 전쟁
- 코딩테스트
- 오픈소스
- git-lfs
- 리멤버나우
- 리멤버나우 요약
- 웹 독학
- pytorch-tutorial
- flask
- 장영준
- 프로그래머스
Archives
- Today
- Total
Nam's
[신발검색엔진][Pre] 신발 이미지 크롤링 본문
유튜버 조코딩 님의 영상에서 도움을 받았습니다. youtu.be/1b7pXC1-IbE
신발 이미지를 학습하기 위해서는 신발 이미지가 많~이 필요하다. 어떻게 신발 이미지를 모을 수 있을까?
가장 쉬운 방법으로는 네이버나 구글에서 신발 검색 결과를 모드 크롤링 해오는 것이다.
하지만, 우리 서비스에서 신발검색엔진에서 결과로 띄워주고 싶은 이미지는 "깔끔한 신발 이미지" 이다.
깔끔한 신발 이미지라 하면, 쇼핑몰에서 썸네일로 보여주는 신발 이미지 같은 것들을 말한다.
따라서 네이버, 구글이 아닌 쇼핑몰 신발 이미지를 크롤링 하기로 결정했다.
첫 번째 타겟은 무신사.
무신사에는 신발 검색 결과 256개 페이지에 각각 90개씩의 신발, 총 24146 개의 신발이 있다.
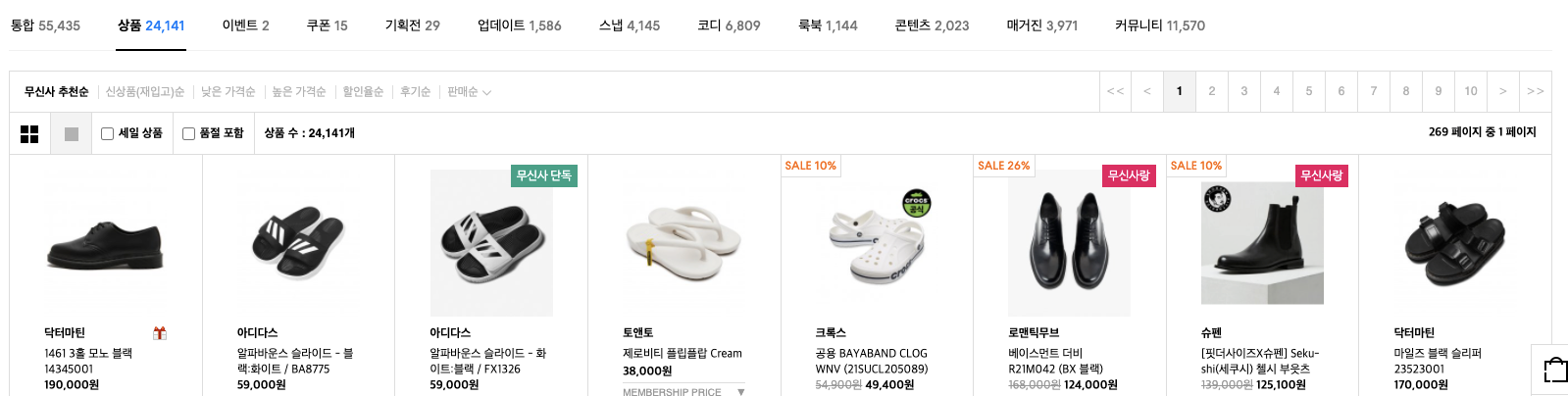
[무신사 "신발" 검색 결과 이미지 크롤링 코드] - github.com/devnjw/ShoeSearch
import os, time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.request
def PageUrl(itemName, pageNum):
url = "https://search.musinsa.com/search/musinsa/goods?q=" + itemName + "&list_kind=small&sortCode=pop&sub_sort=&page="+ str(pageNum) +"&display_cnt=0&saleGoods=false&includeSoldOut=false&popular=false&category1DepthCode=&category2DepthCodes=&category3DepthCodes=&selectedFilters=&category1DepthName=&category2DepthName=&brandIds=&price=&colorCodes=&contentType=&styleTypes=&includeKeywords=&excludeKeywords=&originalYn=N&tags=&saleCampaign=false&serviceType=&eventType=&type=&season=&measure=&openFilterLayout=N&selectedOrderMeasure=&d_cat_cd="
return url
FindingItemName = "신발"
driver = webdriver.Chrome(os.getcwd() + "/chromedriver")
pageUrl = PageUrl(FindingItemName, 1)
driver.get(pageUrl)
totalPageNum = driver.find_element_by_css_selector(".totalPagingNum").text
items = driver.find_elements_by_css_selector(".lazyload.lazy")
print("Total Page of ", FindingItemName, " : ", str(totalPageNum))
cnt = 1
for i in range(int(totalPageNum)):
pageUrl = PageUrl(FindingItemName, i+1)
driver.get(pageUrl)
time.sleep(2)
items = driver.find_elements_by_css_selector(".lazyload.lazy")
print("Finding: ", FindingItemName, " - Page ", i+1, "/",totalPageNum, " start - ", len(items), " items exist")
for item in items:
try:
time.sleep(0.5)
imgUrl = item.get_attribute("data-original")
urllib.request.urlretrieve(imgUrl, "images/musinsa/m" + str(cnt) + ".jpg")
cnt += 1
except Exception as e:
print(e)
pass
driver.close()
*2021.06.24 업데이트
기존 신발 이미지만 불러오던 코드에서, 상품 title, price, brand, shop, 정보를 같이 가져오게 수정했다.
이미지 검색이 서비스 핵심 기능이지만, 키워드 검색은 기본으로 제공하는게 맞는거 같다. 그리고 지금은 웹에 상품 사진만 띄워주지만, 제목, 가격도 같이 띄워주는게 좋을 수도 있을 것 같다.
import os, time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib.request
def PageUrl(itemName, pageNum):
url = "https://search.musinsa.com/search/musinsa/goods?q=" + itemName + "&list_kind=small&sortCode=pop&sub_sort=&page="+ str(pageNum) +"&display_cnt=0&saleGoods=false&includeSoldOut=false&popular=false&category1DepthCode=&category2DepthCodes=&category3DepthCodes=&selectedFilters=&category1DepthName=&category2DepthName=&brandIds=&price=&colorCodes=&contentType=&styleTypes=&includeKeywords=&excludeKeywords=&originalYn=N&tags=&saleCampaign=false&serviceType=&eventType=&type=&season=&measure=&openFilterLayout=N&selectedOrderMeasure=&d_cat_cd="
return url
FindingItemName = "신발"
driver = webdriver.Chrome(os.getcwd() + "/chromedriver")
pageUrl = PageUrl(FindingItemName, 1)
driver.get(pageUrl)
totalPageNum = driver.find_element_by_css_selector(".totalPagingNum").text
print("Total Page of ", FindingItemName, " : ", str(totalPageNum))
for i in range(int(totalPageNum)):
pageUrl = PageUrl(FindingItemName, i+1)
driver.get(pageUrl)
time.sleep(2)
item_infos = driver.find_elements_by_css_selector(".img-block")
item_images = driver.find_elements_by_css_selector(".lazyload.lazy")
print("Finding: ", FindingItemName, " - Page ", i+1, "/",totalPageNum, " start - ", len(item_infos), " items exist")
for i in range(len(item_infos)):
try:
time.sleep(0.5)
title = item_infos[i].get_attribute("title")
price = item_infos[i].get_attribute("data-bh-content-meta3")
item_url = item_infos[i].get_attribute("href")
img_url = item_images[i].get_attribute("data-original")
print("Title: ", title)
print("Price: ", price)
print("Image URL: ", item_url)
print("Image URL: ", img_url)
print()
# Save Image
# urllib.request.urlretrieve(img_url, "../images/musinsa/m" + str(i+1) + ".jpg")
except Exception as e:
print(e)
pass
driver.close()
*2021.07.02 업데이트
가져온 상품 title, price, brand, shop 정보를 Lightsail Database에 저장되는 코드를 추가했다.
불필요한 sleep() 함수도 줄여서 크롤링 시간을 단축시켰다.
def PageUrl(itemName, pageNum):
url = "https://search.musinsa.com/search/musinsa/goods?q=" + itemName + "&list_kind=small&sortCode=pop&sub_sort=&page="+ str(pageNum) +"&display_cnt=0&saleGoods=false&includeSoldOut=false&popular=false&category1DepthCode=&category2DepthCodes=&category3DepthCodes=&selectedFilters=&category1DepthName=&category2DepthName=&brandIds=&price=&colorCodes=&contentType=&styleTypes=&includeKeywords=&excludeKeywords=&originalYn=N&tags=&saleCampaign=false&serviceType=&eventType=&type=&season=&measure=&openFilterLayout=N&selectedOrderMeasure=&d_cat_cd="
return url
class Crawl(Resource):
def get(self):
FindingItemName = "신발"
driver = webdriver.Chrome(os.getcwd() + "/chromedriver")
pageUrl = PageUrl(FindingItemName, 1)
driver.get(pageUrl)
totalPageNum = driver.find_element_by_css_selector(".totalPagingNum").text
items = driver.find_elements_by_css_selector(".lazyload.lazy")
print("Total Page of ", FindingItemName, " : ", str(totalPageNum))
cnt = 1
for i in range(int(totalPageNum)):
pageUrl = PageUrl(FindingItemName, i+1)
driver.get(pageUrl)
time.sleep(2)
item_infos = driver.find_elements_by_css_selector(".img-block")
item_images = driver.find_elements_by_css_selector(".lazyload.lazy")
print("Finding: ", FindingItemName, " - Page ", i+1, "/",totalPageNum, " start - ", len(item_infos), " items exist")
for i in range(len(item_infos)):
try:
title = item_infos[i].get_attribute("title")
brand = item_infos[i].get_attribute("data-bh-content-meta4")
price = item_infos[i].get_attribute("data-bh-content-meta3")
item_url = item_infos[i].get_attribute("href")
img_url = item_images[i].get_attribute("data-original")
shop = "musinsa"
new_user = Item(
title = title,
brand = brand,
price = price,
item_url = item_url,
image_url = img_url,
shop = shop
)
db.session.add(new_user)
db.session.commit()
# Save Image
urllib.request.urlretrieve(img_url, "images/musinsa/m" + str(cnt) + ".jpg")
cnt += 1
except Exception as e:
print(e)
pass
driver.close()'개발 > Side Project' 카테고리의 다른 글
| [신발검색엔진] 02 개발 1주차 - 웹 구현 (0) | 2021.06.26 |
|---|---|
| [신발검색엔진] 01 프로젝트 계획 & 시작 (0) | 2021.06.22 |
| [신발검색엔진][2차 회의] 0508(토) (0) | 2021.05.08 |
| [신발검색엔진][Pre] 신발 Image Detection with OpenCV, YOLO (0) | 2021.05.08 |
| [신발검색엔진][Pre] 사이드 프로젝트 시작 (0) | 2021.04.28 |
'개발/Side Project' Related Articles
more




Comments