
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 110 옮기기
- 오픈소스
- 백준 2193
- 리멤버나우
- pytorch-tutorial
- git password
- Convolutional Neural Networks
- 경제 요약
- 코딩테스트
- cs231
- 딥러닝
- flaks
- 프로그래머스 여행경로
- aws rds
- 리멤버나우 요약
- 알고리즘
- 장영준
- C++
- 스무고개 Metric
- 2003 error
- 2003 에러
- flask
- 웹 독학
- 이베이 매각
- but how?
- git-lfs
- 미국 이란 전쟁
- 뤼이드
- multi-task learning
- 프로그래머스
- Today
- Total
Nam's
[딥러닝] cs231n-03 Loss Function & Optimization 본문
*본문 내용은 스탠포드 대학교 CS231n 강의를 개인적인 학습 목적으로 요약한 내용입니다.
Lecture: Loss Function and Optimization
Slide: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
1. Loss Function
Loss Function: 현재 설정된 W를 입력으로 받아서 각 스코어를 확인하고
이 W가 지금 얼마나 좋고 나쁜지를 정량적으로 말해주는 것
그리고 가장 덜 구린 W를 찾는 과정이 Optimizaion이다.
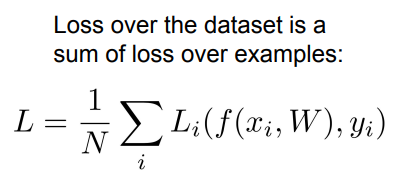
Multiclass SVM loss (Support Vector Machine)

위와 같은 score 결과를 예시로 했을 때, SVM의 원리는 이렇다.
정답 label score 보다 다른 score들 + 1이 작다면 무시한다. 정답 label score보다 높은 경우에는 더한다.
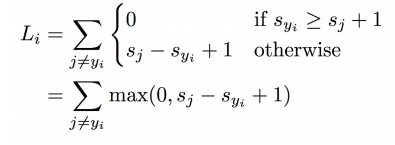
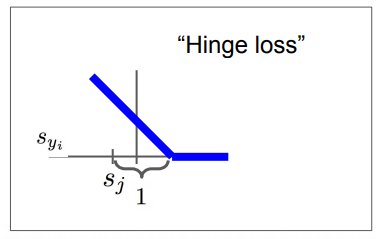
+1 은 margin 인데, 상황에 맞게 다르게 설정할 수 있다.
margin이 어느 정도 있어야 충분히 정확한 예측이라고 할 수 있겠다.
다시 식을 정리해서 표현하면 이렇게 할 수 있다.
max의 의미는 값이 0보다 작을 경우 0으로 threshold 해주는 것이다.
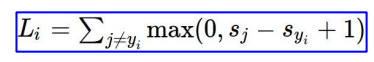
Q: What is the max / min value of the SVM
A: infinity and 0
Q: At initalizaion W is small soall s almost 0. What is the loss?
A: num of classes - 1
정답 라벨의 score 와 나머지 score가 거의 같다면 margin 값만 클래스 개수만큼 늘어날 것이다.
디버깅할 때 자주 사용하는 특징이다.

생각보다 코드는 엄청 간단하다.
margins[y] = 0 은 정답 label은 포함하지 않기 위함이다. (안해주면 margin 값이 들어간다)
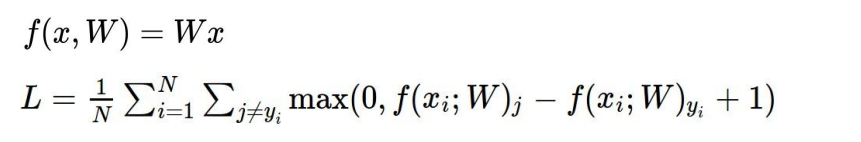
Regularization
모델이 트레이닝 데이터셋에 완벽히 핏하지 못하도록 모델의 복잡도에 패널티를 부여하는 방법이다.
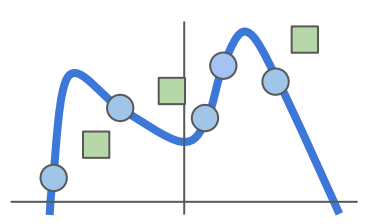
트레이닝 데이터셋을 완벽하게 학습한다면, 위와 같은 울퉁불퉁한 모델이 나올 수 있다.
하지만 test data set (초록색) 이 들어왔을 때, 잘 분류하지 못할 것이다.
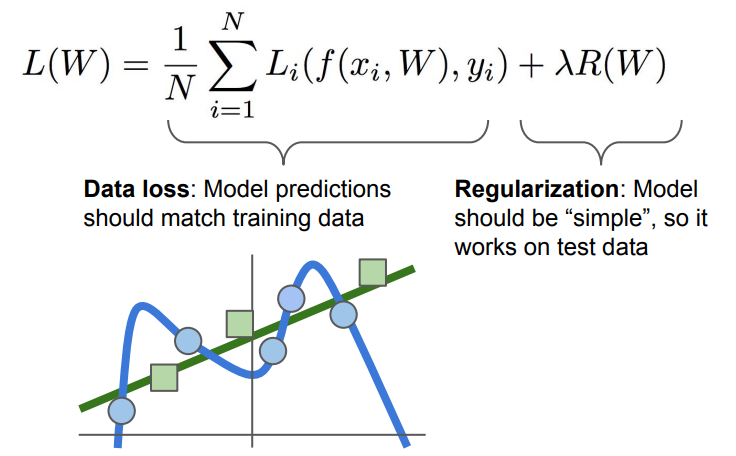
때문에 Regularization이 필요하다. 우리가 원하는 모델은 좀 더 심플해야할 필요가 있다. (오컴의 면도날)

위와 같은 다양한 방법들이 있다.
Softmax Classifier (Multinomial Logistic Regression)
SVM에서의 Loss 값이 Softmax Classifier에서는 확률로 표현된다.

Q1: What is the min/max possible loss?
A1: 0 and 1 => 하지만 컴퓨터는 무한대에 약하기 때문에, log값이 0과 1이 나오는 일은 거의 없다.
디버깅 용
Q2: Usually at initialization W is small so all s ≈ 0. What is the loss?
A2: - log(1/c) = log(c)
SVM과 Softmax의 차이
: SVM의 경우 일정 선(margins)을 넘기면 더이상 성능을 개선하려 하지 않는다.
하지만 Softmax는 정답 클래스는 1로 보내고 나머지는 0으로 보내기 위해서
log 안의 값이 양의 무한대로, 음의 무한대로 '계속' 개선하려고 할 것이다.
2. Optimization
최적의 W를 찾기 위해서 변화의 기울기가 Loss를 줄이는 방향으로 움직이면 된다.
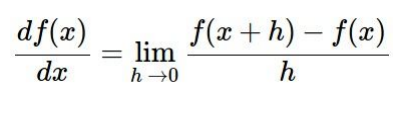
일일이 w를 변화시켜보면서 체크할 필요는 없다.
loss function의 함수를 w편미분 해주면 기울기를 알 수 있다.
Gradient Descent

Step_size: 방향을 알아냈을 때, 얼만큼 나아갈 것이가.
코드를 설계할 때 가장 중요한 parameter 중 하나.
Stochastic Grdient Descent (SGD)
SGD: data가 너무 많으면 W가 일일이 업데이트 되기까지 너무 많은 시간이 걸린다.
그래서 모든 data set을 학습하는 것이 아니라 Minibatch라는 작은 트레이닝 샘플 집합으로 나눠서 학습하는 방법.
Minibatch 는 2의 승수를 주로 사용한다. 32, 64, 128
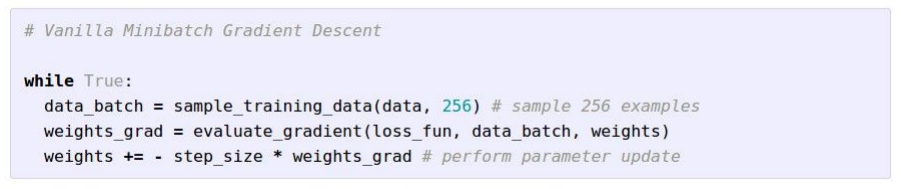
SGD demo: http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/
'개발 > Machine Learning' 카테고리의 다른 글
| [딥러닝] cs231n-05 Convolutional Neural Networks (0) | 2020.03.03 |
|---|---|
| [딥러닝] cs231n-04 Backpropagation & Neural Networks Intro (0) | 2020.03.02 |
| [딥러닝] CS231n-02 이미지 인식의 어려움, kNN, Linear Classfier (0) | 2020.02.27 |


