
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 프로그래머스
- 2003 에러
- 백준 2193
- 딥러닝
- 장영준
- pytorch-tutorial
- but how?
- 뤼이드
- git-lfs
- 경제 요약
- git password
- 리멤버나우
- 미국 이란 전쟁
- multi-task learning
- 오픈소스
- 코딩테스트
- 웹 독학
- 리멤버나우 요약
- Convolutional Neural Networks
- 110 옮기기
- 알고리즘
- aws rds
- flaks
- 프로그래머스 여행경로
- 이베이 매각
- cs231
- 스무고개 Metric
- C++
- flask
- 2003 error
- Today
- Total
Nam's
[오픈소스] PyTorch-tutorial 3/3 활용 및 후기 본문
본 포스팅은 yunjey라는 네이버 개발자가 제작한 오픈소스 프로젝트 pytorch-tutorial 을 다룬 포스팅으로, 공식 튜토리얼과 관련이 없습니다.
지난 포스팅에서 Colab 환경에 pytorch-tutorial의 설치를 마치고 tutorials 디렉토리 안에 단계별 모델들이 있는 것까지 확인했다.

본 포스팅에서는 01-basics 안에 있는 logistic regression 을 실행 및 수정해본다.
1. 코드 살펴보기
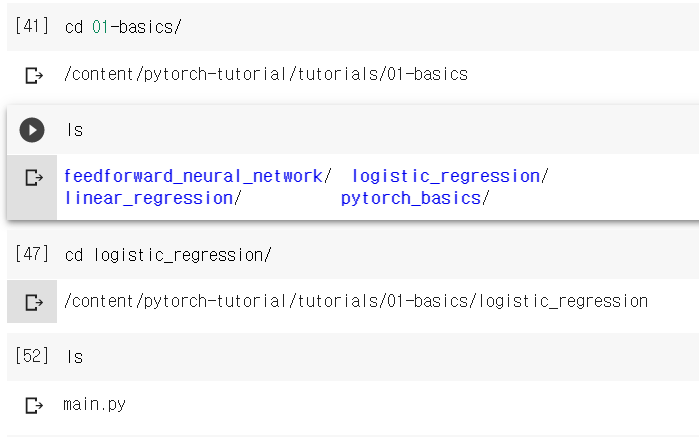
01-basics 디렉토리에 들어가면 4개의 폴더가 있고, 그 중에서 logistic_regression 폴더로 들어간다.
모든 디렉토리에는 main.py 파이썬 코드가 들어있다. main.py 코드를 열어보자.
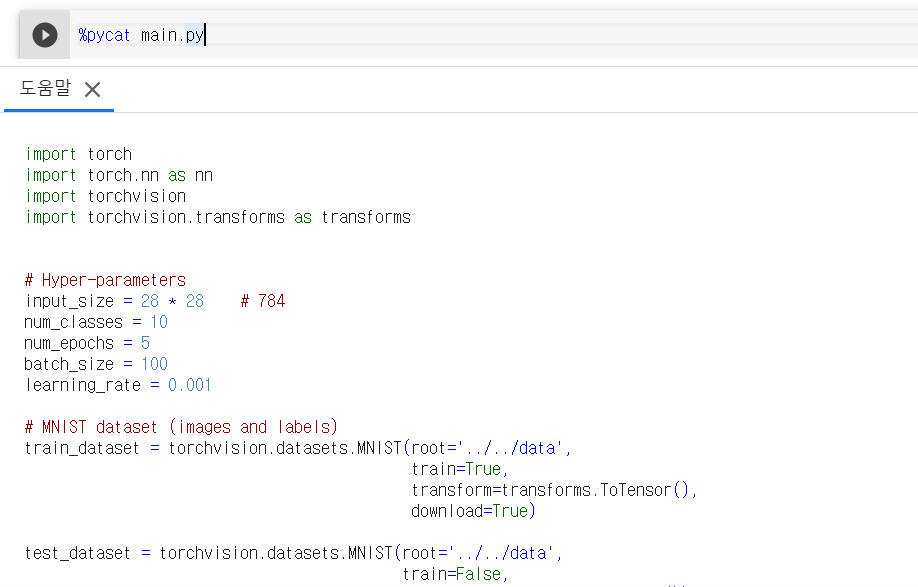
%pycat 코드이름.py를 입력하면 도움말 창이 열리면서 코드를 볼 수 있다.
logistic-regression 모델의 코드는 아래와 같다.
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Hyper-parameters
input_size = 28 * 28 # 784
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# MNIST dataset (images and labels)
train_dataset = torchvision.datasets.MNIST(root='../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='../../data',
train=False,
transform=transforms.ToTensor())
# Data loader (input pipeline)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# Logistic regression model
model = nn.Linear(input_size, num_classes)
# Loss and optimizer
# nn.CrossEntropyLoss() computes softmax internally
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# Train the model
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# Reshape images to (batch_size, input_size)
images = images.reshape(-1, input_size)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.reshape(-1, input_size)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the model on the 10000 test images: {} %'.format(100 * correct / total))
# Save the model checkpoint
torch.save(model.state_dict(), 'model.ckpt')(생각보다 길다)
2. 코드 실행
지금 코드를 모두 이해할 필요는 없다. 한번 돌려보자.
!python 코드이름.py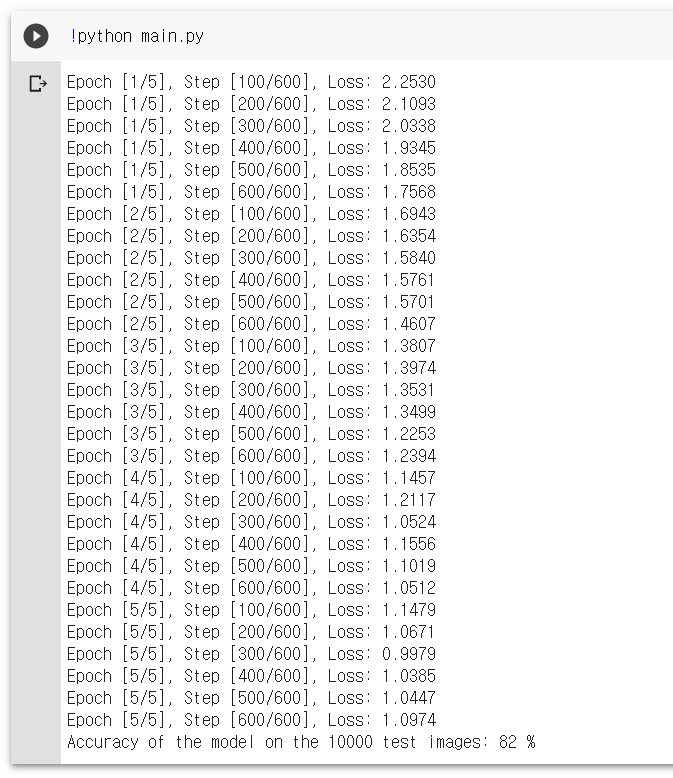
마지막 문장을 보면 10000개의 test image 들을 대상으로 정확도가 82% 나온 것을 확인할 수 있다.
3. 코드 수정 및 실행
이제, 코드를 수정해보자.
Colab 환경에서 직접 코드를 수정할 수는 없고, 위에 했던 것 처럼 코드를 띄우고 복사해서 local에서 수정한 뒤 파일을 새로 만들어야한다. colab 파이썬 코드 수정 방법은 stackoverflow를 참고했다.
%pycat 코드이름.py로 코드를 열고 메모장으로 복사한다.
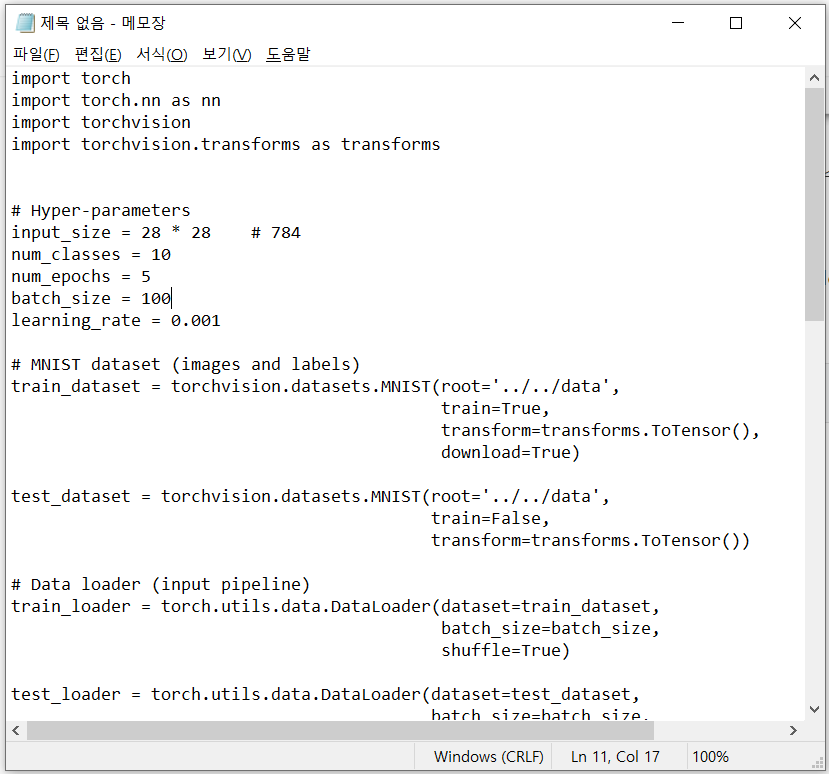
복사한 후 원하는 대로 코드를 수정하면 된다.
나는 epoch을 5 -> 10 으로, batch_size를 100 -> 50 으로 바꿔보겠다.
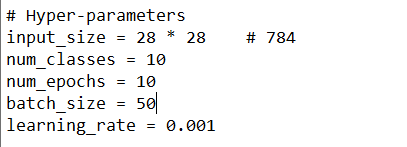
다시 코드를 복사한 후 Colab에 main2.py를 새로 만들어 준다.
%%writefile main.py위 코드 아래에 원하는 코드를 넣고 ctrl+enter를 쳐주면 파일이 생성된다.
이제 변경한 hyperparameter가 결과에 어떤 영향을 미쳤는지 알아보기 위해 main2.py를 실행해보자.
!python main2.py
Hyperparameter를 변경해주니 정확도가 82% -> 87%로 상승한 것을 볼 수 있다.
4. 후기
이렇게 pytorch-tutorial을 설치하고 사용, 수정해봤다.
한국인이 만들어서 그런지 정리가 굉장히 깔끔하게 잘되어 있었다. Dataset을 따로 가져오지 않아도 되게금 준비되어 있어서 편하게 pytorch를 사용할 수 있었다.
이번 포스팅을 작성하면서 의도치 않게 Colab에서 python 수정하는 방법까지 공부하게되어 유익했다.
다음에 기회가 된다면 RNN, imageCaptioning 같은 다른 모델들도 다뤄보고 싶고, hyperparameter도 다양하게 바꿔보면 좋을 것 같다.
'개발 > 전공 과제' 카테고리의 다른 글
| [오픈소스] PyTorch-tutorial 2/3 설치 (0) | 2020.03.11 |
|---|---|
| [오픈소스] PyTorch-tutorial 1/3 소개 (0) | 2020.03.11 |

